Alex has spent over ten years writing about software, hardware, and the latest tech trends. He breaks down complex stuff into clear, no-nonsense reviews and insights. If you want honest takes on new gadgets and digital tools, he’s your guy.
The Strategic Advantage of Automating Server Configuration with Ansible Playbooks
Automating server configuration has become a foundation in efficient IT management, dramatically reducing manual errors while speed uping deployment timelines. How to automate server configuration using ansible playbooks is a topic commanding increasing attention because automation eliminates repetitive tasks, enforces consistency across environments, and improves scalability in complex infrastructures. Through automation, teams achieve higher productivity and reduce downtime caused by misconfigurations or oversight.
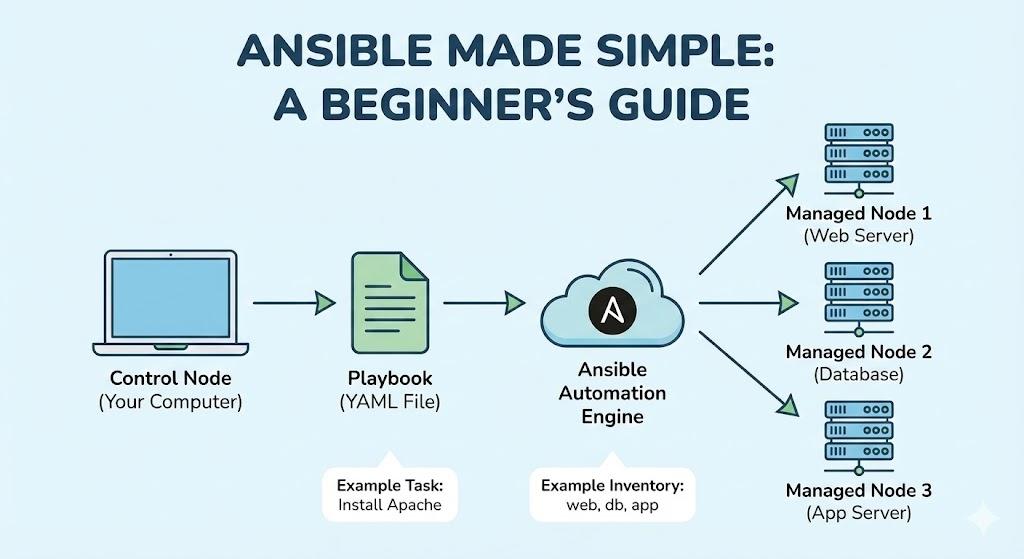
Ansible stands out as a powerful IT automation platform, widely adopted for its simplicity, agentless architecture, and flexibility. The core of its effectiveness lies in playbooks—structured sets of instructions written in YAML. Playbooks bring together tasks, handlers, and roles into structured, reusable definitions that coordinate configuration tweaks, software installs, and service operations across many servers efficiently.
The value of playbooks extends beyond mere automation. As a result, organizations reduce risk through predictable, auditable change management. They provide transparency and version control compatibility, making infrastructure as code (IaC) a practical reality. This codification enables collaboration among teams and builds a culture of continuous integration and continuous delivery (CI/CD).
Several reasons improve playbooks as the preferred method for server automation:
Declarative Syntax: Playbooks describe desired states without detailing the essential commands, freeing administrators from complex scripting.
Idempotency: Re-running a playbook applies only necessary changes, avoiding redundant operations and ensuring system stability.
Modular Design: Tasks can be divided into roles, helping reuse, testing, and scalability in large environments.
Extensibility: The Ansible market supports custom modules and plugins, enabling automation across cloud, network, and on-premises infrastructure.
Agentless Operation: Using SSH and WinRM, Ansible requires no additional software on managed nodes, simplifying security and deployment.
The process of learning how to automate server configuration using ansible playbooks equips teams to handle diverse scenarios—from setting up new servers with precise configurations to applying patches and updates consistently. This approach reduces the mean time to recovery (MTTR) and minimizes human intervention, thereby lowering operational risk (at the time of writing).
Introduction to Ansible Playbooks
Complementing the advantages of playbooks, the integration of Ansible with CI/CD pipelines simplifies infrastructure changes alongside application code deployments (in current public documentation). Such combination builds an agile, DevOps-aligned workflow that boosts overall delivery speed and quality.
The importance of adopting structured testing and validation for playbooks cannot be overstated (based on documented pricing pages). Errors in playbooks can propagate quickly across multiple systems, leading to downtime or security vulnerabilities. Establishing strict testing procedures ensures reliability before deploying changes broadly.
Security proven methods intertwine closely with automation strategies. Proper credential management, least privilege principles, and encrypted communication channels reduce exposure when playbooks are executed. Ansible’s vault feature allows sensitive data to be stored securely within playbooks, reinforcing secure automation protocols.
Learning how to automate server configuration using ansible playbooks open ups major operational efficiency, but mastering the intricacies of writing, testing, and securing playbooks is equally essential. As organizations gravitate towards infrastructure as code, the ability to script complex server states reliably has become a critical skill supported by a strong toolset.
For IT leaders and engineers aiming to sharpen their automation aptitude, the layered benefits of Ansible playbooks—from simplicity to secure scalability—offer a compelling pathway to transform server management workflows. Freeing teams from erroneous manual steps enables them to refocus on strategic projects that drive innovation and competitive advantage.
Setting Up Your Environment for Automation
The foundational knowledge of these automation principles forms a base to explore advanced topics such as multi-tier orchestration, integration with containerization platforms, and workflow optimization through pipelines, which separate superficial automation from true operational excellence.
Using official resources like the Ansible documentation and best practice guides promotes a solid understanding of the evolving automation market, bridging gaps left unaddressed by many current tutorials and ultimately empowering organizations to deploy infrastructure changes confidently and rapidly. Official Ansible resources elucidate key concepts with clarity, supporting this complete learning journey.
The main points
Playbook testing and validation techniques
Security proven methods for Ansible playbooks
Troubleshooting common errors in Ansible automation
Advanced multi-server orchestration examples
Prerequisites and Setup for Effective Automation
The first step involves installing Ansible on a control machine, which typically runs a Unix-like operating system such as Linux or macOS, although Windows subsystems can also function with additional setup. It is key to verify that the Ansible version aligns with 2026’s latest stable release to benefit from security patches and functionality enhancements—older versions may lack playbook syntax improvements or integrate poorly with new SSH features. Before diving into how to automate server configuration using ansible playbooks, establishing the appropriate groundwork is essential. The official Ansible package, maintained by Red Hat, can be installed via package managers like apt or yum on Linux distributions, ensuring compatibility and ease of future updates. For macOS, Homebrew remains the standard tool for installation.
Once Ansible is installed, the next prerequisite mandates established access to all target servers intended for configuration. These servers can exist across various environments, including VPS providers, dedicated data centers, or public clouds. Direct network reachability with low-latency SSH access majorly impacts automation speed and reliability. Administrators must secure credentials or key-based authentication for all hosts, and organize an inventory file using Ansible’s YAML-based format to define host groups clearly. This practice helps targeted playbook runs, enabling efficient parallel execution on subsets of infrastructure.
Generating a strong SSH key pair—preferably Ed25519 in 2026 for superior performance and security—is fundamental. Proper SSH configuration files (/etc/ssh/sshconfig or ~/.ssh/config) can improve connections with persistent multiplexing and reduced handshake overhead, speed uping playbook application across servers. SSH setup must focus on security and smooth connectivity. The public key then requires deployment on each target server’s ~/.ssh/authorizedkeys file, avoiding password prompts during automation cycles. Also, enforcing SSH agent forwarding or using Ansible’s --private-key parameter helps manage key usage securely without exposing private keys on intermediary machines.
Also, Python 3 is a core dependency on both the control and managed nodes, as Ansible’s modules rely on it for execution. Most modern Linux distributions mandate Python 3 by default, but administrators should verify and upgrade if necessary. Complementary Python packages such as paramiko or cryptography libraries may assist SSH functionality, especially under complex key management or encrypted connections.
Continuous network connectivity checks before running playbooks prevent mid-execution stalls. Network prerequisites include ensuring firewall rules allow SSH traffic on port 22 or custom ports if configured, as blocked or filtered access will interrupt automation flows and cause task failures. Testing connectivity using simple Ansible ad-hoc commands (ansible all -m ping) confirms readiness.
Writing Your First Playbook: A Step-by-Step Guide
Lastly, administrators should consider setting up Ansible Vault for sensitive variables like passwords or API keys, incorporating encryption protocols to protect secrets during playbook runs. This approach adheres to proven methods outlined in contemporary security standards, mitigating risks of credential leakage during automation.
This foundational setup block supports reliability, speed, and security, vital elements when exploring the next steps of how to automate server configuration using ansible playbooks with confidence and precision. For those seeking deeper understanding of server hardening techniques, reviewing how to secure your linux server against brute force attacks offers relevant insights.
Step-by-Step Automation Guide for Server Configuration Using Ansible Playbooks
Create Your Inventory File
Start by defining the hosts or groups of hosts you intend to configure in an inventory file, typically named hosts or inventory.ini. This file directs Ansible on where to run the tasks, grouping servers logically to simplify large-scale management.
Define Host Variables (Optional)
If certain servers require unique settings, add host or group variables within the inventory file or in separate variable files. This segmentation ensures custom configurations without cluttering your main playbook.
Write the Initial Playbook YAML File
Construct the YAML playbook file with a clear structure including hosts, become privileges, and a list of tasks. Use descriptive names for the playbook and individual tasks to maintain clarity and ease future maintenance or collaboration.
Specify Tasks with Modules
For each task in the playbook, choose the appropriate Ansible module such as apt for package management, service for controlling system services, or copy for file transfers. Modules abstract complex commands and ensure idempotency in configurations, avoiding redundant changes.
Set Variables and Templates
Incorporate variables within your playbook to handle active values. Use Jinja2 templates for configuration files that require environment-specific adjustments, enabling reusable and flexible playbooks for various scenarios.
Use Handlers for Changes
When certain tasks require service restarts or other follow-up actions only if a change occurs, define handlers and notify them within relevant tasks. This approach minimizes unnecessary restarts and reinforces stability.
Run Syntax Check
Before applying changes, run ansible-playbook with the --syntax-check option to validate playbook syntax and catch errors early. This step prevents deployment failures caused by YAML formatting issues or module misuse.
Perform a Dry Run with Check Mode
Execute the playbook in check mode (--check) to simulate changes without applying them. Dry runs help anticipate the outcome and ensure the intended modifications align with desired configurations, especially in production environments.
Execute the Playbook on Target Hosts
Run the playbook by invoking ansible-playbook followed by your playbook filename and inventory file path. Include the --become flag if improved privileges are required. This command applies the configuration changes across all listed hosts.
Monitor Output and Logs
Observe the playbook’s output in real-time to identify task successes or failures. Retain logs for auditing and troubleshooting purposes, as they provide insights into task execution order and any anomalies.
Verify Configuration on Remote Hosts
After playbook execution, manually or through automation tools, verify that configurations reflect the intended state. For critical settings, write subsequent playbook tasks dedicated to validation, thereby automating confirmation steps.
Iterate and Refine the Playbook
Based on verification results and operational feedback, iteratively update your playbook to handle edge cases or improve efficiency. Version control is recommended to track changes and collaborate effectively.
Integrate Playbooks into CI/CD Pipelines
Embed your Ansible playbooks within continuous integration and continuous deployment workflows to enforce automated configuration management. This integration enables rapid, consistent server provisioning aligned with software releases.
Automate Testing of Playbooks
Implement automated testing using tools like Molecule to validate playbook behavior in isolated environments. Testing identifies syntax errors, dependency issues, or incorrect logic before deployment, improving reliability.
Secure Sensitive Data with Ansible Vault
Protect confidential information such as passwords or keys within your playbooks through Ansible Vault encryption. This practice is essential for maintaining security standards and complying with regulatory requirements.
Schedule Regular Playbook Runs
Use job schedulers or orchestration platforms to run playbooks periodically, ensuring that servers maintain the desired state and drift is quickly corrected. Automation maintains consistency without manual intervention.
Troubleshoot Common Errors
Upon encountering failures, use verbose logging (-vvv option) to gain insights into error causes. Common issues include unreachable hosts, permission denials, or syntax mistakes—resolving these efficiently maintains uptime and operational continuity.
Document Playbook Usage and Changes
Maintain complete documentation detailing playbook intention, variables used, and recent modifications. Well-documented playbooks reduce onboarding time for team members and help smoother audits.
This guided sequence highlights the importance of validation and security—the very pillars of reliable automation practices in modern IT environments. Simply essential. Following these steps constructs a solid workflow that balances precision and scalability when managing server configurations (per industry surveys). Incorporating CI/CD integration further improves operational maturity, cementing Ansible playbooks as a fundamental toolset for infrastructure as code. For additional depth on securing Linux servers, referencing the guide on how to secure your linux server against brute force attacks complements these automation steps with strong protection measures.
Proven methods for Crafting Reliable Ansible Playbooks
Improving Ansible playbooks to automate server configuration requires more than just writing tasks; it demands disciplined proven methods that ensure maintainability, efficiency, and robustness. Thoughtful use of meaningful variable names sets a solid foundation. Explicit and descriptive variable names improve readability across complex infrastructures, enabling teams to understand the intent of every parameter without ambiguity. This clarity reduces configuration errors and speed ups onboarding for new collaborators (at the time of writing). Consistency in naming conventions also prevents conflicts when variables are imported from various sources or roles.
Modularizing playbooks represents another foundation of quality Ansible automation. Instead of a monolithic playbook, breaking down tasks into reusable roles or includes improves scalability and organization. Each role can encapsulate a defined aspect of server configuration, such as user setup, package installation, or security hardening. This approach supports parallel development and testing of individual components and promotes code reuse across projects, effectively reducing duplication of effort and potential errors.
Error handling and graceful failure management must be integral from the outset. Including conditionals like ignore_errors or using block with rescue enables administrators to handle exceptions thoughtfully rather than abruptly halting all automation (in current public documentation). Detailed logging during each stage aids post-run analysis and troubleshooting while minimizing downtime risks. Properly planned error responses can trigger notification systems or rollback routines to maintain system stability when unexpected situations arise.
Idempotency—the principle that running a playbook multiple times results in the same system state—is non-negotiable for configuration management. Carefully writing tasks that first check the current system before applying changes ensures that repeated executions avoid unnecessary actions or unintended side effects. Using Ansible’s built-in modules designed for idempotency, such as apt or yum for package management and lineinfile for configuration files, ensures predictable and reliable automation outcomes.
Other beneficial practices include explicitly defining task dependencies and using Ansible’s tags to selectively run segments of a playbook for focused testing or updates. Using variable files or group_vars to manage environment-specific settings further decouples code from deployment context, making playbooks more portable and easier to update safely.
Common Server Configuration Tasks Automatable with Ansible
For teams integrating continuous integration and delivery pipelines, adhering to these standards ensures that automated configuration steps are repeatable, verifiable, and ready for production environments, making the process far more controllable and auditable. Following these proven methods creates a strong framework that boosts the value of automation and simplifies ongoing maintenance tasks.
Industry documentation, such as that from Red Hat’s Ansible Automation platform, outlines these principles as foundational pillars for professional-grade infrastructure as code management. Adopting a consistent approach supported by meaningful variable naming, modular architecture, error-resilience, and idempotency improves automation workflows and reduces costly downtime or misconfigurations inherent in manual setups. For ongoing improvement, pairing these guidelines with thorough testing regimes and security audits further refines the integrity of server provisioning pipelines and an organization’s operational resilience.
Also, aligning playbook structure with security proven methods and error handling mechanisms disconnects automation from chaos and turns it into a stronghold of controlled environment management (based on documented pricing pages). Integrating playbook testing and validation frameworks embeds early detection of flaws before deployment, a best practice essential for software development lifecycle alignment. This complete methodology supports scaling automation from simple tasks toward enterprise-grade orchestration—an objective many organizations aim to achieve in 2026 and beyond.
Benefits Achieved and Next Automation Milestones
Automating server configuration with Ansible playbooks dramatically reduces manual misconfigurations and speeds up deployment cycles. This approach centralizes control, enabling consistent, repeatable setups across diverse environments without repetitive command-line interventions. Users gain immediate reach into their infrastructure state, allowing errors to surface early and be resolved before cascading into production downtime.
The playbook syntax itself employs YAML, a human-readable structure that lowers the barrier for both developers and sysadmins to write and maintain automation scripts. This clarity eliminates many complexities found in traditional scripting languages, offering a balance of readability and power. The idempotent nature of tasks ensures that running the same playbook multiple times does not cause unintended side effects, a critical requirement for reliable automation.
Integration with version control systems like Git supports collaborative infrastructure changes with full diffusion tracking and rollback capability. Scalability is intrinsic to Ansible’s design; managing thousands of nodes becomes feasible without agents installed on targets, reducing overhead and potential security risks. Also, incorporating Ansible within Continuous Integration/Continuous Delivery (CI/CD) pipelines enables fully automated testing and deployment workflows, aligning server configuration with software delivery lifecycles.
Those seeking to deepen expertise should explore advanced topics such as active inventory management, Ansible roles for modularizing playbooks, and using Ansible Tower or AWX for enterprise-grade scheduling and analytics. Documentation on testing frameworks like Molecule can guide validation of playbook correctness before live deployment, improving confidence in automation accuracy. Also, reinforcing security through vault encryption and proven methods in access control will safeguard sensitive configuration data (at the time of writing).
Master advanced inventory scripts and active resource targeting
Fully integrate automation steps into CI/CD pipelines for continuous rollout
Adopt role-based playbooks to improve reuse and organizational standards
Implement strict playbook testing with frameworks such as Molecule
Secure automation artifacts using Ansible Vault and proven methods
Such continuous learning ensures that the benefits of automation extend far beyond initial implementation, scaling with organizational complexity and evolving infrastructure demands (among the platforms reviewed here). For a more complete understanding, referencing official Ansible documentation and verified community resources provides up-to-date practices and case studies demonstrating the impact of automated configuration management on operational excellence.
Testing and Validating Ansible Playbooks
Expanding knowledge in these areas solidifies the foundation for infrastructure as code and pushs teams towards mature DevOps practices, creating resilient, auditable server environments maintained with predictable precision.
This continuous evolution is key to maintaining competitive infrastructure agility in 2026 and beyond. The journey does not end at automating initial setup; it progresses into full lifecycle automation encompassing monitoring, patching, and self-healing systems that transform IT operations fundamentally. The next steps lie in embedding Ansible playbooks smoothly within broader automation toolchains and cloud orchestration workflows to boost efficiency gains.
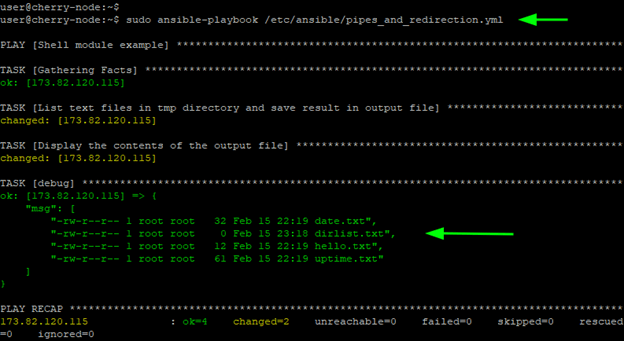
Syntax errors often occur when YAML formatting is incorrect or indentation is inconsistent. Use the ansible-playbook --syntax-check command to identify these issues before execution. Ensuring adherence to YAML standards prevents the playbook from failing during runtime and simplifies debugging.
Managing SSH Connection Failures
SSH authentication errors frequently result from misconfigured SSH keys, incorrect user permissions, or firewall blocks. Verify that your control node has the correct private keys and that the managed nodes accept the corresponding public keys. Checking network accessibility and validating SSH port settings can resolve most connection problems.
Debugging Task Failures Without Clear Logs
Some playbook tasks may fail silently or provide insufficient error messages. To diagnose these, increase verbosity with the -vvv flag during execution to get detailed output. Also, using the ansible.builtin.debug module inside the playbook can help trace variable contents and task outcomes effectively.
Handling Variable Scope and Overwrite Issues
Variables defined in multiple places can cause unexpected values or conflicts in playbook runs. Understand the variable precedence order in Ansible—facts, playbook vars, host vars, group vars, and command-line vars—and ensure variable declarations align with the desired override behavior. Use explicit variable namespaces or unique names to avoid collisions.
Resolving Inventory File Discrepancies
An incompatible or incorrectly formatted inventory file can lead to unrecognized hosts or incorrect targeting. Stick to supported formats such as INI, YAML, or the active inventory script compatible with your environment. Validate the inventory file using the ansible-inventory --list command to troubleshoot host discovery issues efficiently.
Fixing Idempotency Failures in Playbooks
Playbooks should be idempotent—completing without causing unintended changes on subsequent runs. Failing idempotency can arise from tasks not using check modes or unsupported modules. Carefully select modules that support idempotent operations and test carefully to confirm consistent behavior across executions, preserving system state integrity.
Overcoming Module Compatibility Limitations
Some modules may behave differently across Ansible versions or target operating systems. Review module documentation for version-specific notes and platform restrictions. Incorporate conditional task execution and use ansible_version checks to ensure compatibility, avoiding unanticipated playbook failures.
Managing Latency and Timeout Issues in Large Environments
High latency or strict timeout settings can interrupt playbook execution in distributed environments. Adjust SSH timeout and retries settings in the Ansible configuration and improve parallelism with the forks parameter. Segmenting playbooks into smaller chunks or using asynchronous tasks can also improve reliability at scale.
Dealing with Unreachable Hosts and Active Inventory Changes
Network fluctuations or infrastructure updates may render hosts unreachable temporarily. Use Ansible’s retry files or set the maxfailpercentage option to tolerate limited failures without halting the entire playbook. Active inventories integrated with cloud platforms require regular synchronization to keep host lists accurate during automation runs.
Troubleshooting Credential and Vault Access Issues
Incorrect or missing credentials stored in Ansible Vault prevent secure variable decryption and task execution. Always verify Vault passwords or keys and validate access rights. Use Ansible’s built-in Vault commands to encrypt, decrypt, and rekey sensitive data, ensuring playbooks authenticate and apply configurations correctly.
Diagnosing Role and Dependency Failures
Role misconfigurations, missing dependencies, or version mismatches can generate obscure errors during playbook runs. Confirm that all roles are installed via Ansible Galaxy or manually with the correct versions specified in requirements files. Testing roles independently before full playbook integration reduces troubleshooting complexity.
Preventing Race Conditions in Concurrent Task Execution
Simultaneous changes pushed to multiple hosts or shared resources may cause conflicts or inconsistent states. Serialize critical tasks using serial or throttle options and apply locking mechanisms if necessary. Be mindful of dependencies and execution order, especially in complex playbooks managing stateful services.
Debugging Environment-Specific Module Failures
Certain tasks can fail due to differences in underlying software versions or configurations across hosts. Set targeted conditionals to exclude incompatible systems or use when statements to apply environment-specific commands. Regularly update and standardize managed nodes to minimize such failures.
Fixing Playbook Execution Hanging or Timeout
Ansible playbooks hanging indefinitely often result from waiting for unreachable hosts or long-running tasks without timeouts. Use the async and poll parameters to limit execution time on specific tasks. Adjust overall playbook timeouts and monitor logs closely to identify hanging steps.
Dealing with Inconsistent Host Facts Collection
Fact gathering inconsistencies disrupt playbook decisions based on host variables. Disable fact caching temporarily to rule out cache corruption or stale data. Regularly refresh facts using the setup module explicitly, improving playbook reliability in active infrastructures.
Handling Incorrect File and Directory Permissions
Playbooks may fail when attempting operations that require improved privileges or specific access rights. Ensure tasks that modify system files use become: yes to escalate privileges appropriately. Verify that destination directories exist and have suitable permissions to accommodate playbook changes.
Whenever executing playbooks or handling errors, continuous validation through testing environments and integration into CI/CD pipelines is essential as it ensures stable, repeatable server configuration automation that scales effectively in production. Troubleshooting becomes more manageable when combined with complete logging and structured playbook design patterns, supporting reliable infrastructure management into 2026 and beyond.
Modern automation markets complement server provisioning with detailed reports and rollback capabilities, increasing confidence in playbook deployments while minimizing disruption during updates or expansions. For further insights into Linux server security relevant to configuration automation, checking out authoritative documentation on defending against brute force attacks provides a solid foundation in securing automated tasks.